Graph Data Science
In Neo4j, GDS, or Graph Data Science, is a collection of tools and procedures for performing graph analytics using Cypher, the query language of the Neo4j graph database. It includes algorithms for graph traversal, pathfinding, centrality, community detection, and more.
GDS is designed to make it easy to incorporate graph analytics into your applications and processes, whether you are building a recommendation engine, analyzing social networks, or trying to detect fraud or other patterns in your data. It is built on top of the Neo4j graph database, which is a powerful and scalable platform for storing, querying, and analyzing connected data.
Some of the key features of GDS include:
-
A library of procedures and functions for performing various types of graph analytics, including centrality measures, community detection, and similarity calculations.
-
Integration with the Cypher query language, which makes it easy to express complex graph analytics tasks in a simple and intuitive way.
-
Scalability and performance, with the ability to handle large graphs and run complex analytics tasks quickly.
-
Support for real-time analytics, with the ability to stream data into the graph and execute continuous queries.
-
A plugin architecture that allows you to extend GDS with custom procedures and functions.
Overall, GDS is a powerful toolkit for anyone looking to perform advanced analytics on graph data, and it is an important part of the Neo4j ecosystem.
What is Similarity between nodes?
In the context of a graph, the similarity between two nodes refers to how closely related or connected the two nodes are. There are many different ways to measure similarity, and the specific method used can depend on the type of data being represented by the nodes and the type of relationship between the nodes. Some common methods for calculating node similarity include cosine similarity, Jaccard similarity, and Pearson correlation coefficient.
Cosine similarity is a measure of similarity between two vectors, and it can be used to compare the characteristics or attributes of two nodes in a graph. It is calculated by taking the dot product of the vectors and dividing it by the product of the magnitudes of the vectors.
Jaccard similarity is a measure of the overlap or commonality between two sets. In a graph, it can be used to compare the sets of neighbors of two nodes, for example. It is calculated by dividing the size of the intersection of the two sets by the size of the union of the two sets.
Pearson correlation coefficient is a measure of the linear relationship between two variables. In a graph, it can be used to compare the values of a particular attribute of two nodes. It is calculated by dividing the covariance of the two variables by the product of their standard deviations.
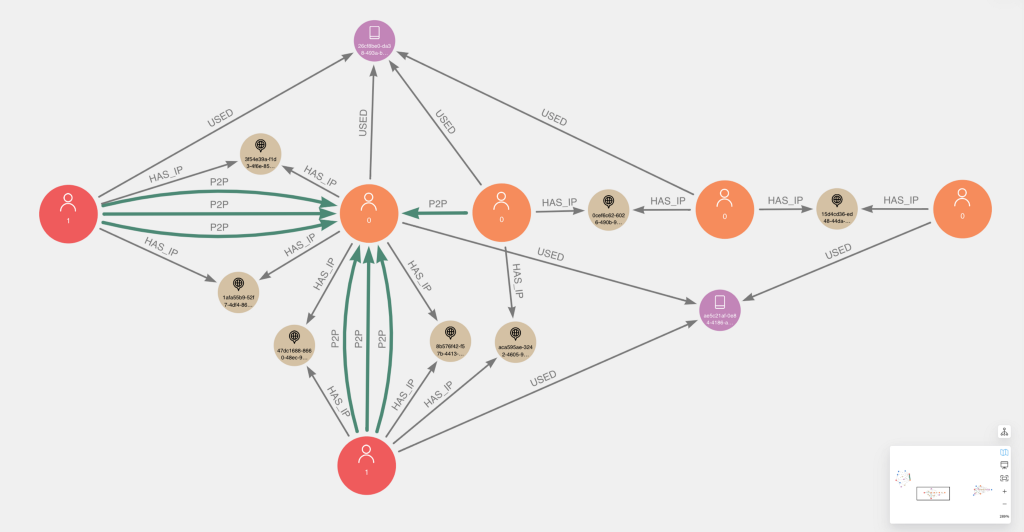
Here is how we can find similarities between two nodes using the following methods:
Cosine similarity
To calculate the cosine similarity between two nodes n1 and n2, you can use the following Cypher query:
MATCH (n1:Node {id: $id1}), (n2:Node {id: $id2})
WITH gds.alpha.similarity.cosine(n1, n2) AS similarity
RETURN similarity
This query will match the two nodes with the given id values and then pass them to the gds.alpha.similarity.cosine function, which will calculate the cosine similarity between them. The similarity value returned by the function will be a float between 0 and 1, with higher values indicating greater similarity between the two nodes.
Jaccard similarity
To calculate the Jaccard similarity between two nodes n1 and n2, you can use the following Cypher query:
MATCH (n1:Node {id: $id1})-[:CONNECTED_TO]-(n2:Node {id: $id2})
WITH size((n1)-[:CONNECTED_TO]-(n2)) AS intersection, size((n1)-[:CONNECTED_TO]-()) + size((n2)-[:CONNECTED_TO]-()) - intersection AS union
RETURN intersection / union AS similarity
This query will match the two nodes and their connections, and then use the size function to calculate the size of the intersection and union of the sets of neighbors of the two nodes. The Jaccard similarity is then calculated by dividing the size of the intersection by the size of the union. The similarity value returned by the query will be a float between 0 and 1, with higher values indicating greater similarity between the two nodes.
Pearson correlation coefficient
To calculate the Pearson correlation coefficient between two nodes n1 and n2, you can use the following Cypher query:
MATCH (n1:Node {id: $id1}), (n2:Node {id: $id2})
WITH n1.attribute AS x, n2.attribute AS y
RETURN gds.alpha.similarity.pearsonCorrelationCoefficient(x, y) AS similarity
attribute property for each node. It will then pass these values to the gds.alpha.similarity.pearsonCorrelationCoefficient function, which will calculate the Pearson correlation coefficient between them. The similarity value returned by the function will be a float between -1 and 1, with higher values indicating a stronger positive correlation between the two nodes and lower values indicating a stronger negative correlation.