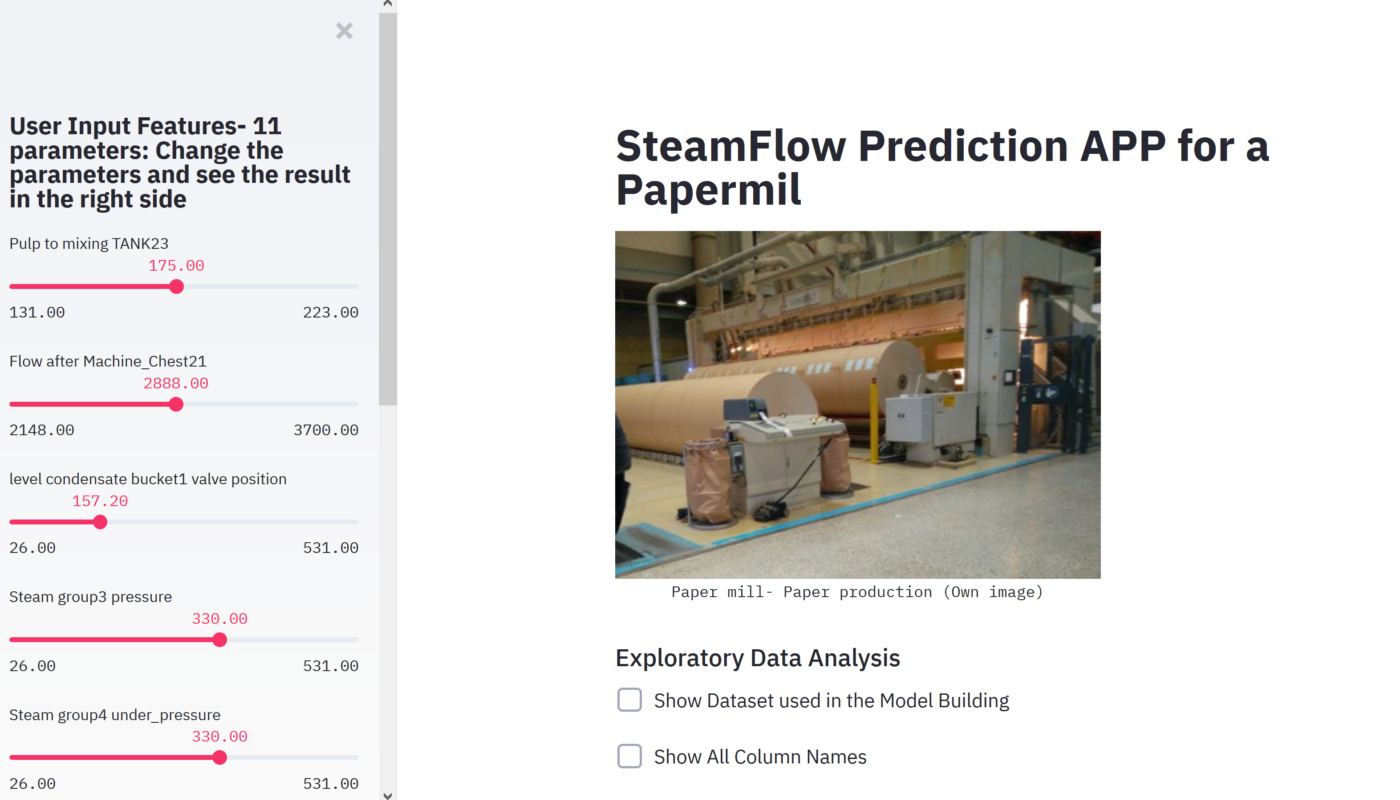
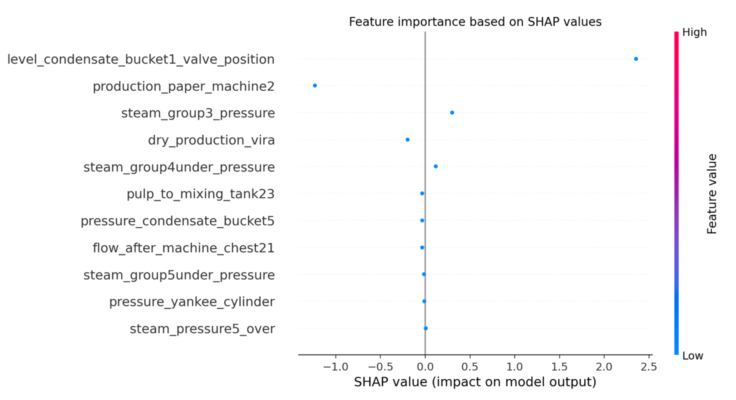
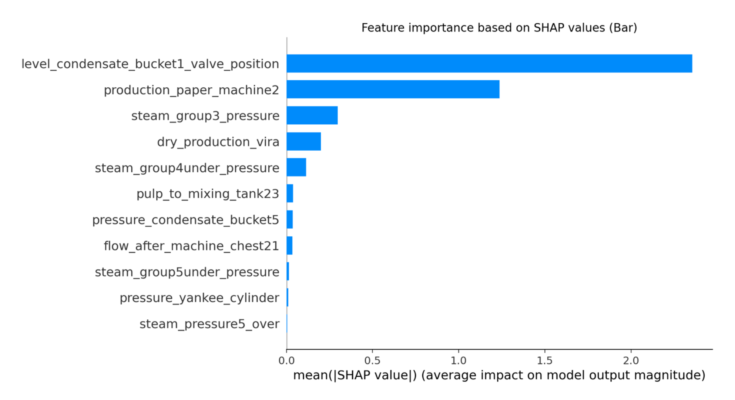
Pulp and paper is one the biggest of the process industries of Sweden. Making paper roll requires water, usually a roll of paper may need 16-22 tons of water per hour. Digitization of process industry like pulp and paper can take months and years. We try to digitize one part of the paper mill by predicting the water flow of a paper machine to make a paper roll using machine learning methods. We have collected the data of a paper machine and we will use few different machine learning algorithm and apply the best which has less error, to see the output prediction and try to show the explainability of the model.
Pulp and paper is one the biggest of the process industries of Sweden. Making paper roll requires water, usually a roll of paper may need 16-22 tons of water per hour. Digitization of process industry like pulp and paper can take months and years. We try to digitize one part of the paper mill by predicting the water flow of a paper machine to make a paper roll using machine learning methods. We have collected the data of a paper machine and we will use few different machine learning algorithm and apply the best which has less error, to see the output prediction and try to show the explainability of the model.
The machine learning pipeline
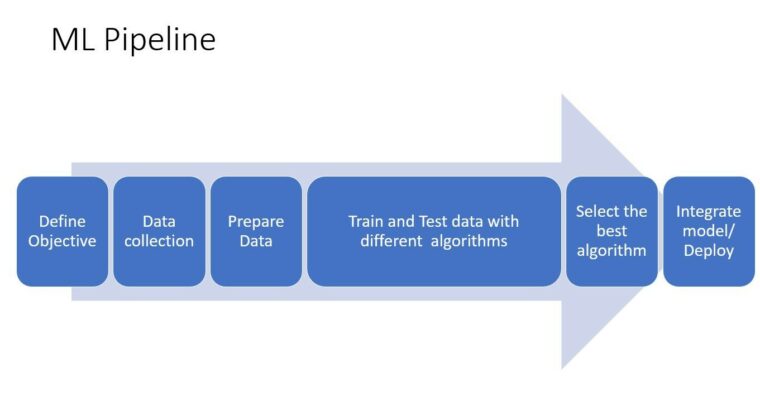
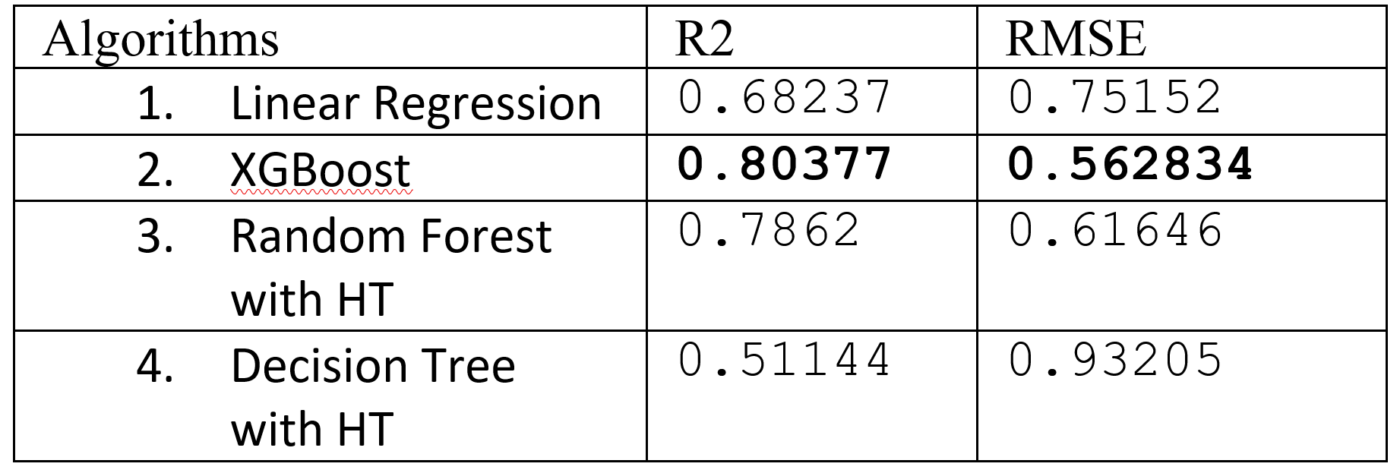
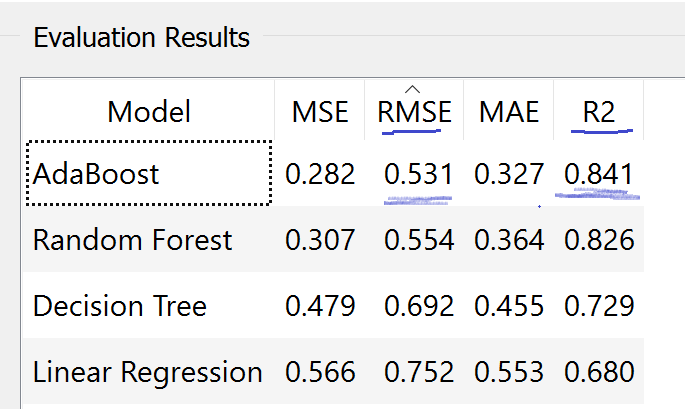
To predict the steam flow or any kind of prediction process we need to go through the machine learning pipeline. Machine learning pipeline is nothing else but a process of implementing machine learning or predictive analytics process, starting from data gathering, data preprocessing, training and testing and deployment.
Orange 3
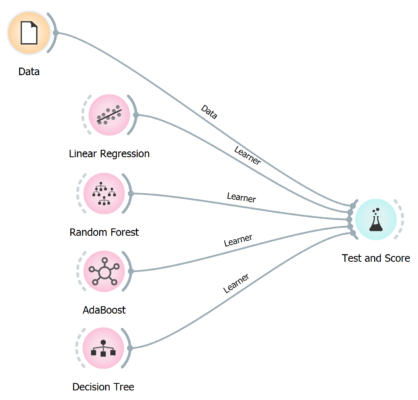 Now we do the same thing with the Orange 3 data mining tool. It’s an open source data visualization, data mining, and analysis toolkit. Where data mining and machine learning is done through visual interfaces.
Now we do the same thing with the Orange 3 data mining tool. It’s an open source data visualization, data mining, and analysis toolkit. Where data mining and machine learning is done through visual interfaces.